Stack-based Buffer Overflow - Part 1
by h3xduck
23 May 2021There exists lots of tutorials online about the all-time classic buffer overflow, but on this post I am trying to offer a new perspective - more visual and providing all the background needed for the understanding of the technique.
Review on memory architecture
Before going on with the technique, it is important to understand how memory works. Feel free to skip this part if you already know about it.
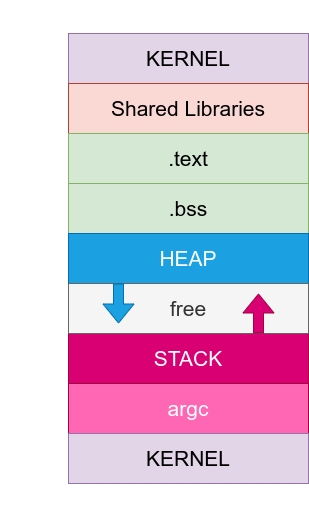 Memory works as a finite list of entries (called words) which can be accessed (either for reading or writing) via a memory address. We will be using a Intel x86 architecture, so the memory addresses are of the form 0xAAAAAAAA, where the “0x” means it is an hexadecimal number. Memory addresses go from 0x00000000 up to 0xFFFFFFFF.
Memory works as a finite list of entries (called words) which can be accessed (either for reading or writing) via a memory address. We will be using a Intel x86 architecture, so the memory addresses are of the form 0xAAAAAAAA, where the “0x” means it is an hexadecimal number. Memory addresses go from 0x00000000 up to 0xFFFFFFFF.
Memory is partitioned so that elements are grouped into sections belonging to a common component:
- Lower and upper memory addresses usually belong to the Kernel code.
- Starting from lower memory addresses we can find shared libraries, the .text segment (which contains the code of programs) and the .data segment (containing static global variables).
- We can find the Heap which starts on lower memory addresses and grows to higher memory addresses. Memory on the stack can be dynamically allocated (and deallocated) by the programmer. Global variables are also stored here.
- There is also the Stack which starts on higher memory addresses and grows to lower memory. It is a LIFO-like structure where local variables (between others) are stored by the processor during the execution of a program thread.
Apart from this, we should also highlight the most important registers on IA-32:
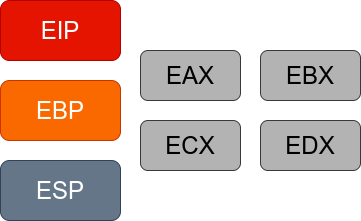
- EIP: Extended Instruction Pointer - Points to the memory address of the next instruction to execute. Similar to the Program Counter in Risc-V architectures.
- ESP: Extended Stack Pointer - Points to the memory address where the next stack operation will take place (such as in push and pop instructions).
- EBP: Extended Base/Frame Pointer - Points to the start of the stack frame. Constant through operations, does not change but when changing subroutines.
Apart from those, there also exist other registers such as EAX, EBX, ECX… which are general purpose registers.
The Stack
Having seen how memory works on Intel x86, let’s now study what we are most interested in: the stack. In order to exploit something we always need to deeply understand how it works.
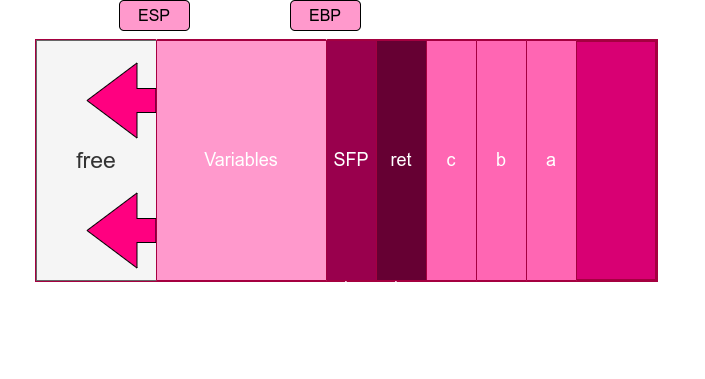
The figure above shows how the stack grows when calling a subroutine. For example, in a program invoking a function f1(int a,int b,int c); we would have the following events (mapped to the figures shown in the scheme above):
- push of the function arguments a, b, c in reverse order.
- call of the subroutine f1. Internally, this takes the value of EIP and pushes it into the stack (so that the program knows where to go back when ending the subroutine). We can see the save EIP as ret in the diagram. Then, we change EIP to the selected subroutine start.
- push of the EBP to the stack. This frame pointer was still the old one from the previous subroutine, and we want to recover it after the subroutine ends too. We can see it in the diagram as SFP.
- mov of the ESP to the EBP. Now the EBP points to the stack frame of the new subroutine.
- add, sub… to ESP. Or any instruction to add space to our stack for our variables. The ESP always points to the end of the stack.
In Part 2 of this post we will apply all the knowledge we have got about memory architecture and IA-32, and see how it can be used for understading how a buffer overflow works and how it can be taken advantage by an attacker.
See you there!
h3xduck
tags: stack - overflow - buffer - exploitation - shellcode - assembly - IA-32 - Intelx86 - memory - registers - code - execution
This work is licensed under a Creative Commons Attribution 4.0 International License.