Stack-based Buffer Overflow - Part 2
by h3xduck
23 May 2021Stack-based Buffer Overflow
In the previous part we reviewed the necessary knowledge about the memory layout and how subroutines are called in IA-32. We are now ready to study how buffer overflow works, and how we can exploit it to achieve arbitrary code execution.
Take for example a very simple vulnerable code:
#include <string.h>
void foo(char *bar){ // bar may be larger than 12 characters
char buffer[12];
strcpy(buffer, bar); //no bounds checking
}
int main(int argc, char *argv[]){
foo(argv[1]);
return 0;
}
Let’s say we run it as follows:
./program MALICIOUSPAYLOAD
The string “MALICIOUSPAYLOAD” would be copied into the buffer, so ESP would be adjusted accordingly to reserve an space for the variable (12 bytes in principle, although in practice it depends because of memory alignment). Then, the strcpy() function will copy character by character the contents of bar, but in this case since there are more than 12 bytes the string will overflow the space previously allocated in the stack and overwrite other contents. Specifically, we could overwrite SFP and ret, and everything else which is positioned on higher memory addresses than the buffer.
Back to the more complex stack we presented on part 1, where we have more variables and arguments a, b, c, a hypothetical buffer overflow would look like follows:
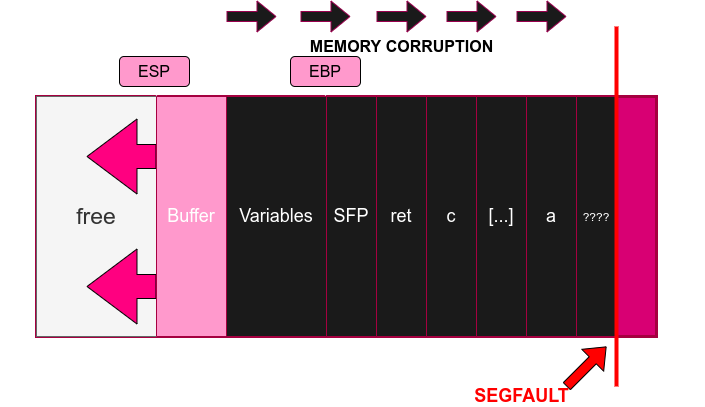
Those sections coloured in black consists of memory addresses whose content has been overwritten by our overflowed buffer. The program, at first, does not know that those stack sections are being overwritten (the program might even have a legitimate reason to do it) but at some point the overflow might even go too up on the stack and reaches a restricted memory location. It is at that point that the program is stopped.
And what would happen if the buffer stops overflowing before writing into a restricted area? Would it signal SEGFAULT too? The answer is not really. At first, the program would continue its execution, since EIP has not been overwritten, even if it is operating with invalid data (the variables in the stack are all modified), but the program does not know that anything happened yet. It is at the point when the subroutine ends that the program realizes of what happened:
- It pops the SFP and sets it to the EBP. It will point to a wrong location because we overwrite it.
- Most importantly, we recover ret from the stack, and set its value to the EIP. Since ret was overwritten, two things may happen:
- EIP points to an area which is not executable, out of the program scope, or simply restricted. We finally receive SEGFAULT because we don’t have execution permissions and the program stops.
- EIP now points to a valid memory address in the program scope. This is the critical point of the buffer overflow. The next time we fetch an instruction to execute, we will fetch it from memory address = EIP. But what will execute? We do not know, but it will be done anyways, because computers do not make a distinction between instructions and data as long as we have the permissions.
The power of the buffer overflow relies on the last point which was made. Since we can change the value of EIP, we can actually redirect the execution of our program to wherever we want! (as long as it is valid). We can, in fact, redirect the execution to a memory section where we have stored our own, malicious code. This payload could be entered via a program argument, or be stored somewhere else on accessible memory.
Shellcode and the NOP sled
Given that we need to store our malicious payload somewhere in memory beforehand, we need to be cautious about the length of it. Since it is common to use the malicious payload itself to overflow the stack, we need to know where exactly we will start overflowing the buffer, and specially at which overflowing bytes we will start to modify ret. We also want ret to be the memory location at the start of our malicious code, so that it is successfully executed. The execution, therefore, would happen as follows:
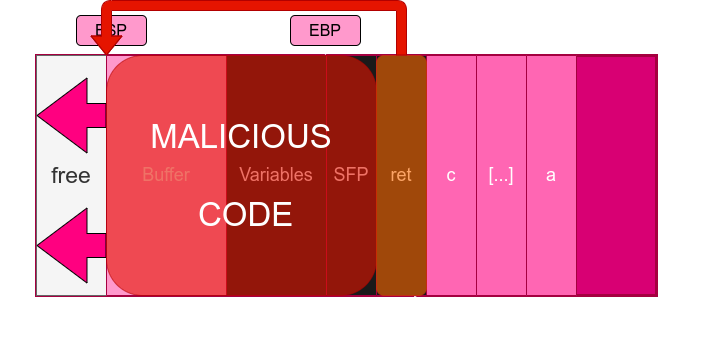
As it can be seen in the picture, we overwrite the stack with our malicious code and we place on ret the starting address of it. But what exactly is that “malicious code” of our payload?
Payloads consist of the so-called shellcode, groups of assembly instructions whose opcodes have been extracted and put in a serial manner. Since the code programmed in a compiled programming language -such as C- is visibly transformed into assembly instructions, it is therefore easy to effectively obtain the opcodes from most programs, generating their corresponding shellcode. The objdump tool included in Linux is very useful for this purpose.
A problem, however, usually arises when trying to repeat the process described above in the real memory of a real system: we usually miss the start of the shellcode by a few bytes. This is because even though we can efficiently analyze at which address to set the stored ret, in a working environment memory experiments subtle but important changes, moving around a bit during the execution of the program. We need some way of amplifying the “landing area” of the shellcode, that is, make it possible to successfully launch it independently on whether it starts at 0x00002220 or at 0x0000222f as long as the memory address specified in ret falls between that area. This is when the concept of NOP sleds appears.
NOP sleds are nothing but empty instructions (the typical nop assembly instructions) which, in their corresponding shellcode form, are included before the start of the important malicious code to ensure that if we started from any of those NOP instructions then the execution flow itself will lead us to the start of the shellcode. In IA-32, the opcode of NOPs are \x90. Note that NOP sleds reduce the memory space available for our payload, in return to a greater probability of success.
The final form of our buffer overflow is then the following:
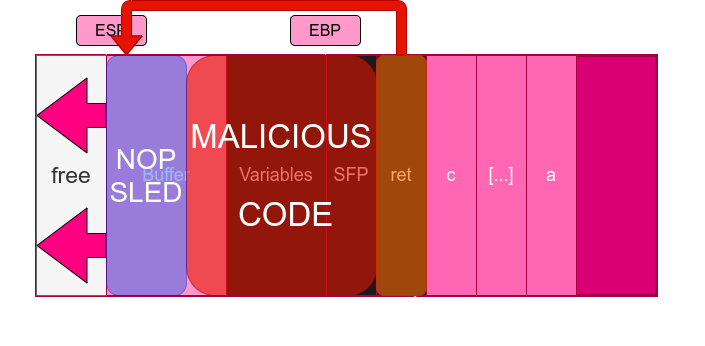
h3xduck
tags: stack - overflow - buffer - exploitation - shellcode - assembly - IA-32 - Intelx86 - memory - registers - NOP - sled - code - execution
This work is licensed under a Creative Commons Attribution 4.0 International License.